Around 2017, we heard from an inventor who’d grown dissatisfied with the IP research firm he’d been working with. He owned a patent dating to 2005 that had to do with the automated conversion of written text into audible speech. Specifically, the processes described in the patent would allow text-to-speech conversion that approximated the sound of the human voice—as opposed to the canned, digitized speech of the kind heard from androids in legacy science fiction movies.
Achieving this effect is considered to be one of the most vexing challenges in the field of speech synthesis technology, and the inventor suspected that his patent had a great potential for monetization. We tended to agree. But we knew that it wasn’t enough to simply own compelling IP. In order to help the inventor monetize his patent, we would have to show that the technology it described was being used by others, ideally by major companies in the context of popular, mass-produced products.
If we could do that—demonstrate conclusively that our client’s patent was being infringed upon—he would be able to sell the patent for millions of dollars to another large company. In turn, as the new owner, that company might sue infringers for damages, or approach them to request licensing fees. Alternatively, they could simply keep the intelligence on file for future reference—perhaps to contribute to a defensive patent strategy, designed to shield them from legal action somewhere down the line. (Individual inventors aren’t generally in a position, financial or otherwise, to pursue such strategies directly.)
The trouble was that the kind of hard evidence we needed is hard to come by. On the other hand, there was good news: In recent years, text-to-speech products offered by major tech companies had gained increasing prominence, offering the very same feature described by our client’s patent. We suspected that some of these products were infringing on his IP. But suspicion isn’t enough.
It is very difficult to convince a buyer to shell out millions of dollars for a patent—or anything else—on the basis of a hunch. Any potential buyer of our client’s patent would know that companies accused of patent infringement will almost always fight tooth-and-nail to avoid paying damages or licensing fees, which can easily run to tens of millions of dollars. So to give the patent value, we would need incontrovertible proof that one company or more was using exactly the technology that the patent described. And the IP search firm that the inventor had been dealing with hadn’t been able to deliver it.
This was hardly surprising. Silicon Valley giants have nothing to gain by making the ins and outs of the tech they’re using easily accessible, lest someone follow their lead—or accuse them of patent infringement. And over the years, through trial and error, we’ve learned that coming up with the kind of evidence that our clients need demands what we think of an investigative approach: a willingness and ability to follow hard-to-decipher trails of clues, venturing out, away from our screens, to do hands-on research.
In this article, we’ll explain how we proved our case through an investigation that took us from deep web searches to a series of highly technical tests conducted on some of the most innovative technology on the market. We’ll explain how we experimented on a suite of text-to-speech products, performing a battery of progressively more focused tests and then carefully analyzing the data that we collected. In the end, we’ll show how we helped our client monetize his patent, resulting in a multimillion-dollar sale.
Note: If you want to learn more about how GreyB can assist you with monetizing your company’s patents, you can contact us here.
How We Designed an Investigation to target fortune 500 companies
After speaking with the inventor and analyzing his patent, we determined that in order to prove infringement, we would need to establish that the text-to-speech products offered by the big tech firms—we focused on those produced doing three things:
- Analyzing textual input on the basis of two levels of abstraction: word level and phoneme level (defined below)
- Gathering those categories of abstraction into separate windows for analysis
- Producing output (speech) that included scaled prosodic contours (defined below)
To begin searching for the definitive evidence we needed, we performed what we call a detailed infringement analysis. Like virtually all IP research projects, we began this one with a powerful, fine-grained digital search—in this case for product manuals, videos, articles, discussion forums and more. Any source that might provide details about the way a product works can come into play. It’s an essential step. But it’s rarely, if ever, enough to prove a full overlap between a patent and another company’s product—the gold standard in this kind of patent monetization project.
In the case of our client the inventor, this proved true. As it turned out #2 was relatively easy to prove—that feature was described in various documents pertaining to the products we suspected of infringement. But #1 and #3 were another matter. We could find no trace of them in the literature, and we didn’t yet have the evidence that would allow our client to monetize his patent.
And as we suggested above, there were complicating factors. As with an increasing number of high-tech products, the publicly available literature about text-to-speech synthesis devices provides virtually no meaningful information about the inner workings of the machine.
Some IP researchers would have stopped there, but although the specifics of this assignment were both knotty and highly specialized, we’d seen obstacles of this kind before. For our clients, turning back at this stage is never an option. And in our experience, successful patent monetization analysis almost always requires further investigation, in the form of some hands-on experience with the relevant products. To prove patent infringement in this case, we knew, we were going to have to spend some quality time with those targetted products and figure out how to show, precisely, how they functioned.
What We Talk About When We Talk About “Text-To-Speech Conversion”
Before we go any further, it’s worth pausing to clarify what exactly we needed to test for in this patent infringement analysis.
Phoneme? Scaled prosodic contour?
For most of us, this is not everyday vocabulary. And yet, these terms describe some of the most basic elements of speech, of how the human voice works. Within the context of a given language—English, for our purposes—a phoneme is simply a perceptibly distinct unit of sound that distinguishes one word from another. So, for example: p, b, d, t in the words pad, pat, bad, and bat.
Prosodic contours are a bit more complicated. Prosody describes the stress and intonation of a given utterance—the perceived pitch and rhythm of a segment of speech. A prosodic contour is a curve or wave pattern representing a perceived pitch or rhythm over time. If prosodic contours are scaled, it simply means that the segments of speech that they represent have been compressed and/or stretched, extending and/or abbreviating individual units of sound.
This is how we talk, emphasizing or downplaying syllables depending on how and why we’re using a word—and on what words or sounds come just before and after it—drawing out vowels or cutting short consonants according to context. As such, a text-to-speech conversion product that has been successfully designed to approximate human speech will produce scaled prosodic contours. Earlier generations of text-to-speech conversion methods, which rely on jamming together syllables from a preloaded bank of sounds, won’t.
As we mentioned above, achieving naturalistic prosodic contours is considered to be one of the most vexing challenges of speech synthesis technology—and hence, for a savvy inventor, one with great monetary potential.
How We Tested at the Word and Phoneme Level
Of course, in everyday life, evaluating whether speech is generated by man or machine, (practically) no one stops to consider whether the source of that speech is properly modulating the pitch, rhythm, and emphasis of words and syllables, or to analyze whether the source is giving too much or too little time to a given sound. We know whether or not speech sounds human just by listening to it.
But to prove that the tech giants’ text-to-speech products were accomplishing their mimicry of human speech by following the processes described in our client’s patent, listening would not be enough. We’d have to look under the hood, using software to interface with the products’ output, and plotting the resulting waves and curves on a series of graphs for analysis:
- Where did the pronunciation of words and sounds begin and end?
- How did pitch rise and fall over time depending on the phonemes in a given utterance?
To answer these and other questions, we would need to design actual tests: get the devices, record what they do, graph the results, mathematically analyze them, and make conclusions. Again, this work is more typical of an engineering lab than a patent search firm but that is the basis of our investigative approach: getting our hands dirty to actually prove infringement (or lack thereof).
How We Tested for Proposition #1
Proposition #1 was actually two separate propositions, requiring two separate sets of tests:
- The product analyzes textual input at the word level
- The product analyzes textual input at the phoneme level
Below, we give a detailed account of how we proved that big tech’s text-to-speech products were analyzing input at the word level. At the conclusion of that process, we applied similar tactics to arrive at proof of same for input at the phoneme level. We give an abbreviated overview of that step, too. It was no less important to the overall success of the investigation. (The testing involved was technically dense, and for the sake of simplicity—and brevity—we will largely allow our explainer on word-level testing to represent the way we thought through the challenges associated with Proposition #1.)
Word-Level Testing
Our goal here was to show that the text-to-speech conversion products would modulate the way a word was pronounced based on what we thought of as “higher-order” factors—part of speech, position in a sentence or utterance—as opposed to “lower-order” factors, e.g. individual syllables or phonemes. To do so, we’d have to figure out how to identify and isolate changes in output (speech) that resulted strictly from variations in these higher-order factors. That is, of course, if such changes existed.
In this we faced two major, interrelated challenges:
- It’s very hard to vary higher-order factors without also making phoneme-level changes, complicating the task of proving that only higher-order (word-level) information has affected the output.
- A probable solution to this challenge, we believed, would be to use a word whose phonemes were identical, even when it appeared in different parts of speech, several times in the same sentence; “dive,” for example, which could be deployed as a noun, an adjective, and as a verb. The trouble with this, however, was that placing “dive” in different parts of a sentence, where it would be preceded and followed by different phonemes, could create confusion as to whether variations in the prosody of “dive” arose from word-level adjustments or lower-order, phoneme-level adjustments.
To reduce the possibility that observed differences in prosody were attributable to lower-level factors, we worked our way through a succession of experiments. Although our first attempts proved inconclusive, they provided additional clues, allowing us to further refine our approach.
To begin, we tried comparing the wave patterns of sentences that were syntactically similar, but which surrounded “dive” with different phonemes. (Admittedly, these sentences were nonsensical; we were interested in form, not content.)
Dive fast and far, dive into a dive bar, but go take a dive.
Dive high and low, dive under a dive bar, but do try a dive.
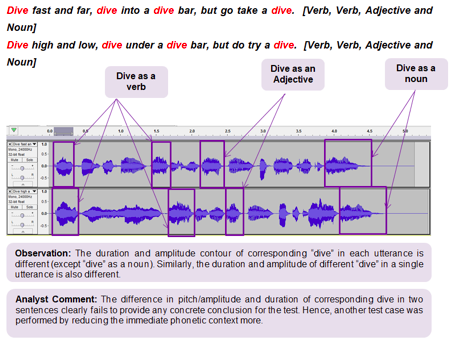
But as the graph above shows, the difference in pitch, amplitude, and duration of “dive” varied too much from sentence to sentence to yield any concrete conclusion about the source of that variation—even when the word occupied the same place in both utterances. Next, after some further brainstorming, we shortened the utterance under review, removing extraneous words.
Dive into a dive bar taking a dive.
Dive under the dive bar doing a dive.
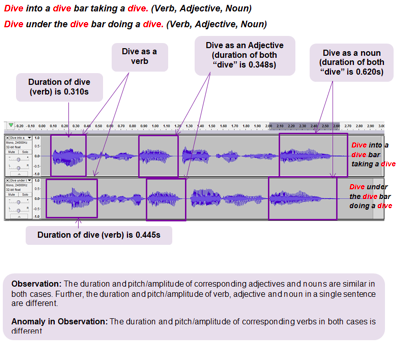
But again, we found too much variation from sentence to sentence between the correspondent uses of “dive,” e.g. when used as an adjective or as a verb. As a third strategy, we tried combining the tactics from the first two experiments, keeping the part of speech for “dive” constant while varying the surrounding phonemes within a very short sentence.
Dive and dive and dive. (Verb, Verb, Verb)
Dive then dive then dive. (Verb, Verb, Verb)

Still, the results were inconclusive. But the results were becoming clearer—as were the mistakes we had made in our initial tests. We were zeroing in on something. Finally, we stripped extraneous words from our test sentence entirely, while using “dive” in three different parts of speech:
Dive dive dive (Verb, Adjective, Noun)
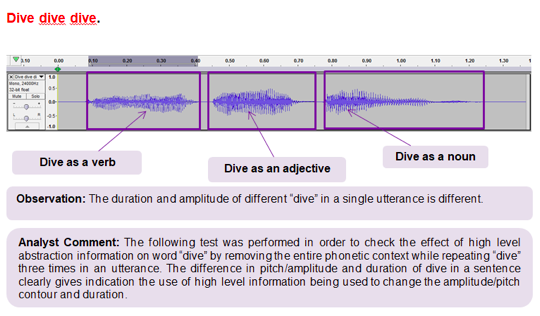
As the graph above shows, the differences in pitch, amplitude, and duration of “dive” as used in this sentence clearly indicate the use of higher-order (word-level) information to vary the word’s prosody. In other words, exactly what we were looking for: definitive evidence that the text-to-speech conversion products that we suspected of patent infringement were analyzing textual input at the word level.
We needed to prove the same thing for input at the phoneme level. And we approached testing much the same way, working through a series of experiments that held some factors constant while varying others: the length of sentences or utterances, the context in which phonemes appeared (e.g. hit, bit, fit), or phonemes themselves (e.g. hoot, hat, hit, hut). As in our word-level tests, each step in the process brought us closer to our target, allowing us to refine subsequent experiments.
Ultimately, by running tests in which all variables were held constant, with the exception of single phoneme, we were able to prove definitively that the text-to-speech products made by top companies were analyzing textual input at the phoneme level.
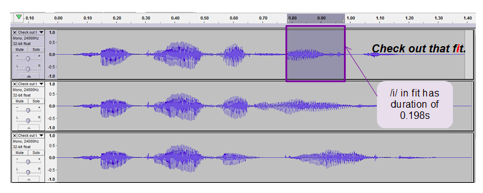
How We Tested for Scaled Prosodic Contours
Now that we had what we needed to show that the text-to-speech systems made by the big tech companies were analyzing input at both the word and phoneme level, it was time to move on to the next phase of our investigation. In addition to the evidence we’d already gathered, we would need proof that these same systems were also producing output (speech) that included scaled prosodic contours. Once again, this would involve a series of tests.
Testing for Duration and Pitch Variety in Words and Phonemes
As a first step, we needed to establish that in synthesizing speech, the TTS products under review would vary the duration of a phoneme or word depending upon input conditions, such as syntactic role, or position in a phrase, sentence, or other utterance. The central challenge in this task was not unlike the ones we’d faced in the earlier stages of our investigation: figuring out how to accurately attribute variations to their true source. In this case, the most likely source of red herrings was the sound production method itself, a technique known as concatenative synthesis, which assembles short samples to create user-customized sequences of sound. The trouble was that concatenative synthesis is itself known to produce variations in duration, which could potentially be mistaken for variations attributable to input parameters: syntactic role, position, and the like.
As a solution, to reduce the possible effects of concatenative synthesis on variations in duration, we pursued a series of strategies designed to isolate and identify the true sources of observed variation in phoneme and word duration:
Varying syntactic roles at a fixed position in a given utterance:
Train as much as you can with a train. (Verb, Noun)
Train tracks are the best way to train. (Adjective, Verb)
Train by train they came here to train. (Noun, Verb)
Experiment with a very lengthy utterance, varying only elements in the middle, where the sound production method is unlikely to have an effect:
The truth is that whenever I decide to train a train to stop at a train platform things go crazy both at home and abroad. (Verb, Noun, Adjective)
The truth is that whenever I decide to fly a fly into a fly swatter things go crazy both at home and abroad. (Verb, Noun, Adjective)
The truth is that whenever I decide to task a task master with a task things go crazy both at home and abroad. (Verb, Adjective, Noun)
While the A set of tests yielded no concrete conclusions, set B quickly showed promise. And by executing it roughly 10 times, using different sets of phonemes and words, we were able to show that, as we suspected, the TTS products that we were testing were varying word and phoneme duration as a function of input conditions including syntactic role and sentence or utterance position.
By repeating much the same testing process, we also succeeded in the next step of our investigation—proving that the pitch assigned by the TTS products to words and phonemes would vary depending on input parameters like syntactic role and position in utterance. In this phase of the investigation, we also demonstrated pitch variation within phonemes.
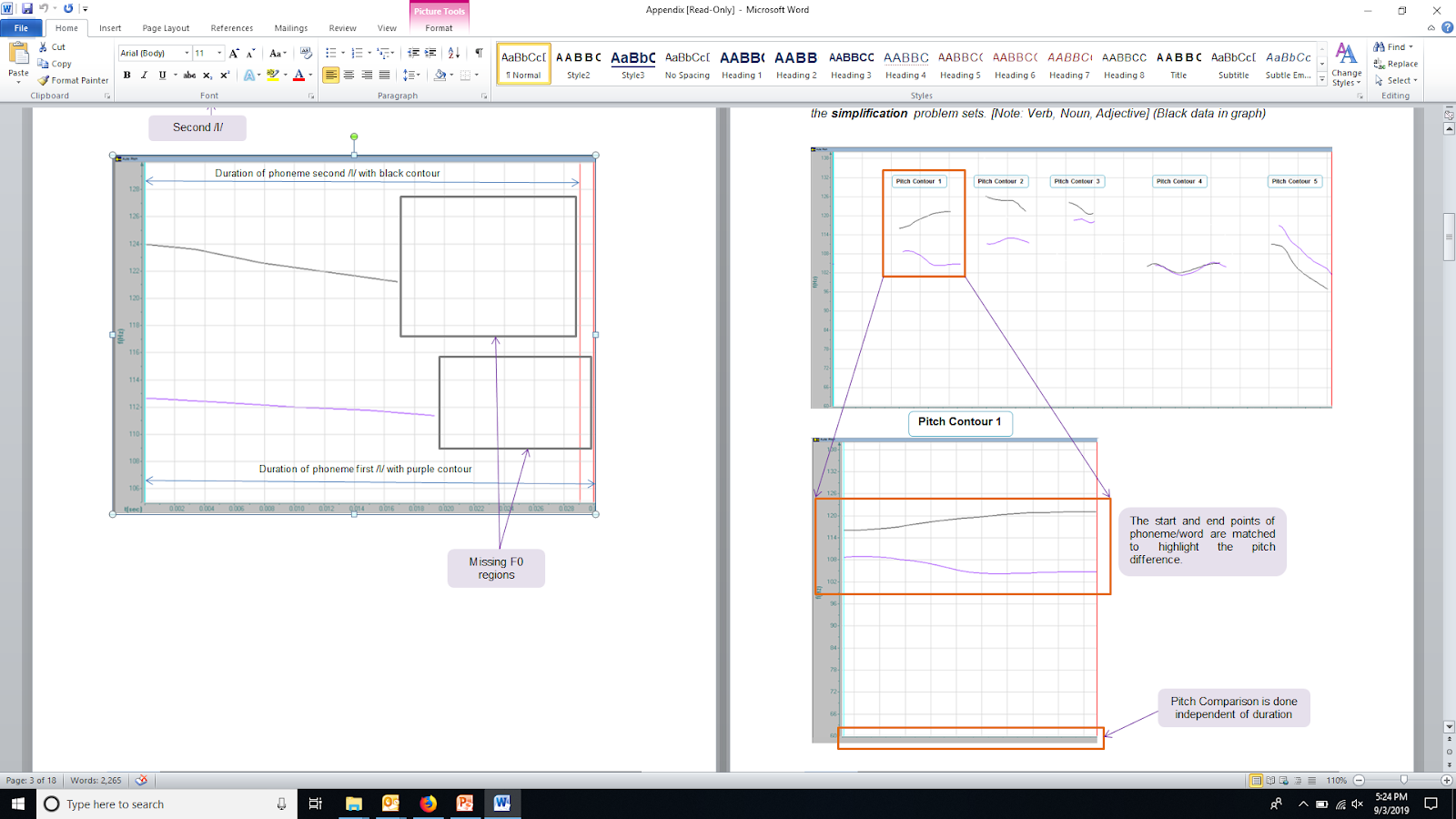
Testing for Scaling
Finally, we had arrived at the final stage of our investigation, having so far gathered all of the evidence we’d been looking for in order to prove that the targetted companies were marketing TTS products that infringed on our client’s patent. What we needed now was proof that the pitch contours (a sub-genre of those prosodic contours we discussed earlier) produced by these text-speech-products were scaled according the duration of the words and phonemes with which they were associated. Put another way, we had to verify that the pitch contours were being stretched and/or compressed over time to reflect variations in the duration of a given word or phoneme.
This sounds rather complicated. And there were a couple of significant hurdles. For one, as in previous stages of this investigation, there was the problem accurately attributing the source of variation to the feature in question. In this case, to scaling, rather than to contextual changes, for example. Ambient noise also had the potential to muddy the observed pitch signal, making accurate analysis challenging.
But as we plotted the results of our experiments, we also found that scaling had a kind of “tell.” By looking for inflection points in pitch contours within phonemes, we began to see certain patterns—a given number of inflection points per phoneme. This suggested a method of output designed for stretching or compressing pitch as a function of word of phoneme duration.
To prove that this was the case, we designed tests to compare the pitch of corresponding phonemes. As a reference point, we used a low-duration phoneme, examining a longer-duration phoneme for temporal scaling. The pitch of the longer-duration phoneme was stretched in time to match its desired temporal duration. If the comparison of the pitch contours was done independent of time, and the final pitch contour of the longer-duration phoneme proved identical to the pitch contour of our reference point, we could conclude that the phoneme was temporally scaled.
For example:
The person knew that to experience an interview I had to go through a painful experience while speaking in front of an experienced person. (Verb)
The person knew that to experience an interview I had to go through a painful experience while speaking in front of an experienced person. (Noun)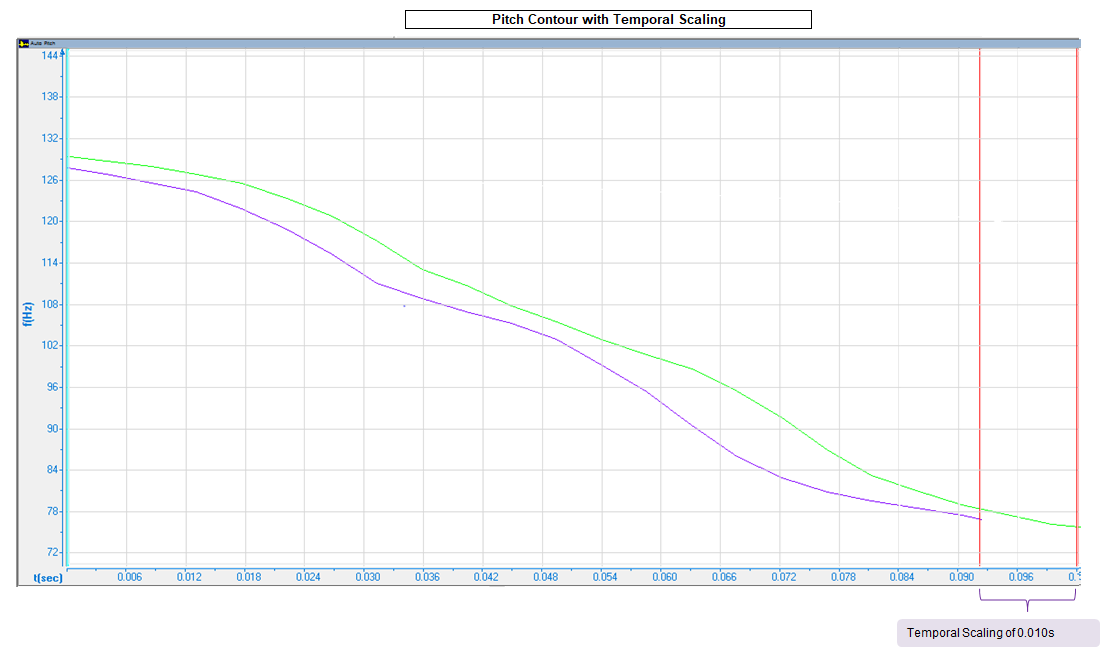
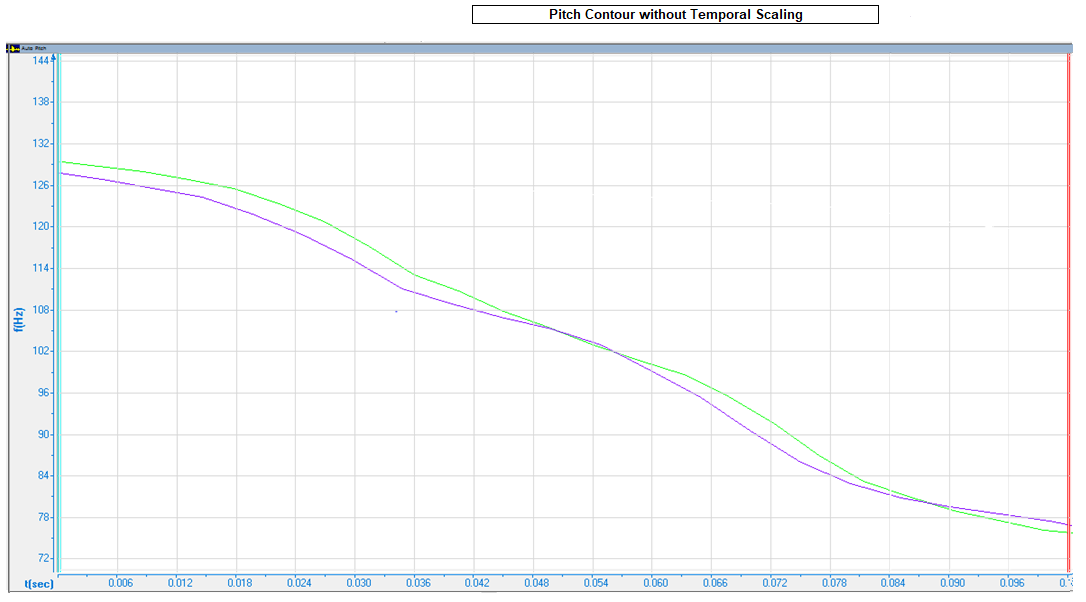
In this case, one of the phonemes /i/ (purple) was found to have lower duration than another phoneme /i/ (green), as pictured above. When the pitch of both phonemes was stretched in time, their pitch contours were similar, indicating that phoneme /i/ (green) was temporally scaled.
Through these and other tests, we were able to collect the evidence necessary to demonstrate conclusively that our client’s patent was being infringed upon by text-to-speech products offered by major tech companies.