I won’t pretend that reading patents is the most thrilling activity in the world. As a user experience designer at a patent research firm, I’ve spent more time than I care to admit poring over patents. Now that I come to think of it, that’s because I was making two trivial mistakes while analyzing these patents.
But hey, it’s not all bad – at least the frustration of it led me to develop utilities that can help you avoid these mistakes. What are these mistakes, and how can a simple utility help you dodge them?
Let’s hop on to it. Trust me. It’s more exciting than it sounds!
1. Reading the Entire Patent to Find the Problem-Statement
Analyzing patent documents is a crucial task for researchers and businesses alike. After all, it provides insights into the latest innovations and emerging technologies that solve industry challenges. And especially when it comes to tracking your competitors’ progress.
So, It’s no surprise that tons of patent sets are taken at the beginning of each project to ensure that all relevant information is accounted for.
However, In the fast-paced world of corporate projects, time is of the essence, and every minute counts. And the process of identifying key problem statements in a patent document is the exact opposite of it- long, tedious, and error-prone.

Let’s take the following patent, for instance. Can you try to find the problem statement discussed in the patent? (start a stopwatch while you’re at it.)


Cracked it? How much time did it take you to do it manually?
The estimated reading time of the patent itself is ~30 minutes. Add to it the re-reading of complex terminologies and deducing the problem statement, and you lose a solid hour to just one patent!
I was facing similar pain, and it was costing me hours at a stretch.
If only I could see the patent in a problem-statement view and analyze the relevant ones accordingly, right?
Well, skimming through patents and going through each paragraph, I knew some sections clearly defined the problem statement. But they were hidden so deep in the fine lines digging through each patent took me forever before I could reach them.
Even though slowly the progress was on the line, I realized no matter how much hard work, this system needed to be fixed.
So, I integrated an algorithm built by our data science team and trained for years over our internal search strategies.
Finally, after 5 years of learning, it could generate a problem statement that was not only accurate but also time-saving.
Here’s the output from the algorithm on the above patent-

Can you guess the time it took to find the problem statement?
Less than 2 seconds.
A SATURATED GIST FOR 6,000 WORDS OF PATENT DATA IN THE BLINK OF AN EYE!!!
Isn’t it just amazing!!
Now I can quickly skim through a patent, find its problem-solution, prioritize its relevance, and save tons of time on patent chunking during my research.
Imagine what a mistake it’d have been if I had kept reading the patents manually!

Don’t just take my word for it. Try it yourself.

Moving to the 2nd mistake we make while reading patents.
2. Are you searching for just Drones? What if the inventor used UAV?
When figuring out if the patent was relevant or not, so many parameters are considered, but the fastest one is to find the most relevant keywords and make a search string.
So I would go for the keyword search (which is one of the most used features in SLATE’s algorithm to find relevant patent sections quickly). But there is a problem with a single keyword search.
Let’s understand this with a simple example:
Say you are searching for a Led Zeppelin song using a keyword search, but only use the song title or the band’s name as the search term. Doing so, you may miss out on relevant songs that use different terminology, such as “rock ballad” or “classic rock anthem” for the song “Stairway to Heaven”.
Similarly, in patent sets, there could be a high chance the keywords you are searching might be different than in different patent texts.
So I devised a plan where AI lets the user add as many combinations of words, their synonyms, and anything close to it and search the entire file for all the combinations. How cool is that!?
So, in your quest to explore Led Zeppelin, a search for keyword clusters could be helpful in expanding the search to related keywords and synonyms, such as “guitar solos” or “70s rock music”. By using a search combination for keyword clusters, you can find a wider range of Led Zeppelin songs that are relevant to their search and ultimately find the specific song you were looking for, like “Stairway to Heaven”, which some might say is the ultimate “rock anthem” or “guitar solo masterpiece”.
The word ‘X’ has 20 synonyms, and another word, ‘Y’, has 30 synonyms. You can use this combination power to search 600 keywords in no time!!
Now imagine the same concept applied to the IP domain.
What if you can search multiple combinations of keywords across an entire patent set and quickly skim through the most relevant ones by their density of occurrence on each patent?
How easy could it be to search from thousands of lines of patent data in combination with the important keyword clusters?
That’s how I created a minimap for keyword clusters on Slate. Now, I can easily find the most relevant patent keywords to make my searches faster and more efficient.
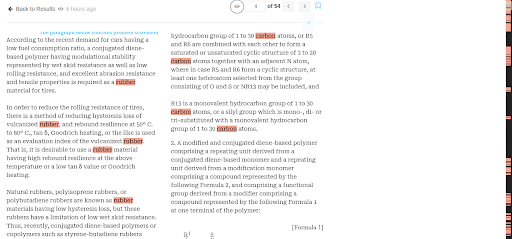
When searching for your targeted keywords, the minimap on the extreme right helps you find out the density of occurrence of those keywords across the entire patent.
This will help you quickly sort and categorize the relevant patents and chunk off the patents that have insufficient or no relevant keywords.
Killing two birds with one arrow:
1) Search for the most relevant keywords and crazy combinations across the patent text.
2) Quickly skim and sort relevant patents in a huge set of patent data with the help of minimaps. (Pace was always my thing!)
3) (Brownie point) Never miss a crucial patent because it didn’t contain the exact target keyword but rather a related term.
Conclusion
In conclusion, by streamlining and optimizing the process of patent analysis, companies can quickly and accurately extract relevant information, identify opportunities, and ultimately drive innovation and growth.
Shucks, I forgot the above words sound just as boring as a patent reading job would be without SLATE, so here’s my entry for a conclusion that SLA(ys)TE.
“Say goodbye to long hours of reading dry and boring patent documents and hello to faster and more accurate results. With the emergence of AI and clever design principles, we’ve tackled some of the most frustrating and inefficient aspects of patent reading. Robots helping us make sense of all that legal jargon- now that’s a useful AI application!” *wink-wink”

Managing your workload with the latest tech and design standards is like having a secret weapon! Not only will it make your work more efficient and productive, but you’ll also feel like a boss doing it.
Reading large patent sets can be dramatically sped up if you avoid these mistakes. And the best part is, with SLATE, you don’t even need to worry about them!
Authored By: Anirudh Vashisht, Software Development