


Managing your Organization’s Data in an efficient manner
Have you ever spent a lot of time sifting through information that already exists within your organization? Has it ever happened that the internal knowledge of all the past projects got overlooked by the assigned team member and you ended up working on similar projects from the scratch over and over again?
54% of US office professionals surveyed agreed that they spend more time searching for documents and files they need than responding to emails and messages.
– Wakefield Research — a survey of 1,000 US office professionals
Researchers would confirm this is a bog-standard yet prevalent problem faced by many of them. Yes, there exists knowledge bases/management tools to help teams avoid redundant work and have better access to their organizational knowledge. You might even be trying one out.
However, each organization has its unique way of institutionalizing its knowledge. And even though there are dozens of such tools in the market; finding the one that could fit in your organization, can be pretty oof!
But what if you pick up one of these tools and get it customized according to your organization’s needs?
Imagine having an internal knowledge base tool made specifically for keeping and indexing different types of data and content that are generated by big research teams such as yours.
Yes, it’s possible Spotter.
What is Spotter and how is it different from other knowledge management tools?
Spotter, in simple words, is designed to work as an advanced document search engine.
You can think of it as Google for your organizational data. You simply enter a search query and it goes through all of the available information stored within your organization to fetch the most relevant results.
What makes Spotter more efficient than a basic internal knowledge base?
For starters, the Spotter interface is built on top of an advanced patent engine developed in-house at GreyB. This engine adds an intelligence layer to the tool, which can make searching and analyzing patent data a breeze.
This patent engine tries to extract important sections from the patent documents. Additionally, it highlights references to other applications within the document. This can help save a lot of time while performing the analysis and find ‘Tier I’ results from the stack of documents already analyzed in the past within a matter of minutes.
Spotter uses state-of-the-art OCR technology to make the text inside images searchable, that too in multiple languages (German, Chinese to name a few). It also provides offline multi-linguistic query suggestions and translations for scenarios where people from remote locations with different native languages work together in an organization.
When it comes to searching features, apart from the simple AND, OR & NOT operators, it supports advanced text-based operators as well. Such as in-sentence searching using the ‘S’ operator and near word searching using the ‘D’ and ‘W’ operators.
There’s all this and a lot more that Spotter can do. In fact, we have been using this tool a LOT while working on our internal projects. Let me take you through one such recent instance.
How Shelza invalidated a patent Ft. Spotter?
Working on thousands of research projects for a decade now has led us to explore a lot of tech areas in depth. Thus, it’s common for us to have Deja-Vu feels when working on tech we have circled through in the past.
Something similar happened to my colleague – Shelza. While working on a patent invalidation project related to the Safe driving mode feature of a phone.
Crux: When the driver starts the car, to avoid distracted driving, his phone is automatically put to the safe mode that pauses any notifications.
“distracted driving”, Shelza had a hunch that someone in GreyB had already worked on a similar concept. She was only looking to find a few good leads. Like a keyword that someone else has used in the patent, a specific company she can track, etc.
She logged into Spotter and entered ‘distracted driving’ in the search bar and let the tool work on it. Within seconds she got around 49 results filtered from tens of thousands of previously analyzed documents.
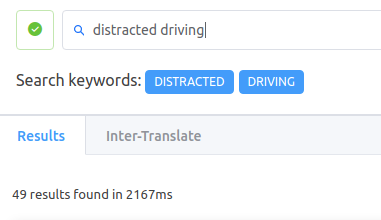
How did the result turn out?
Well, not only was Shelza able to shortlist a relatively smaller set for analysis, but she also found an X reference (previously analyzed by a different team) in the very first 10 documents. Spotter highlighted the relevant text right there and she immediately picked the result. A patent that was a Y reference for someone else was a X reference for the case she was working on.
It was our collective aha! Moment. Imagine the client’s surprise when we were able to get him a X reference on the first day of the search. We had earned a repeat client that day.
Why Spotter?
We built Spotter to solve a quite pressing problem. Not just ours, but of a lot of research teams who produce a ton of research work in a company.
Spotter not only helps us double-check whether we have worked on a particular tech before, but it also helps us extract leads to direct our research strategy using past data.
And all in all, it saves us from “reinventing the wheel” situations.
With a tool like that in hand, inventors, patent attorneys, and R&D departments can be empowered to make informed strategic decisions while avoiding expensive pitfalls and maximizing the commercial value of innovation.
Having an internal knowledge base like Spotter gives you access to all the knowledge produced and previously acquired by your firm. All the documents, papers, images, reports, files, on the network at your fingertips.
That was just one of the many ways Spotter works in our favor. But it’s no fun reading stories instead of trying it yourself right?
Fill the form below and we can get a demo set up ready for you.
Author: Sarthak Jain, Product Development Team

{kind=link}